판다스는 라이브러리는 데이터를 수집하고 정리하는 데 최적화된 도구이다.
판다스는 시리즈(Series)와 데이터프레임(DataFrame)이라는 구조화된 데이터 형식을 제공한다.
판다스는 서로 다른 여러 가지 유형의 데이터를 공통의 포맷으로 정리하는 것이 목적이다.
시리즈
데이터가 순차적으로 나열된 1차원 배열의 형태를 갖는다.
인덱스(index)는 데이터 값과 일대일 대응이 된다.
딕셔너리를 시리즈로 변환하게 되면, 딕셔너리의 키(key)는 시리즈의 인덱스(index)에 대응되고, 딕셔너리의 각 키에 매칭되는 값(value)은 시리즈의 값(value)으로 변환된다.
리스트를 시리즈로 변환하게 되면, 인덱스를 별도로 정의하지 않으면 default로 정수형 위치 인덱스(0, 1, 2, ...)가 자동으로 지정이 된다.
사용 방법
| pandas.Series(딕셔너리) | |
| pandas.Series(리스트) |
예시
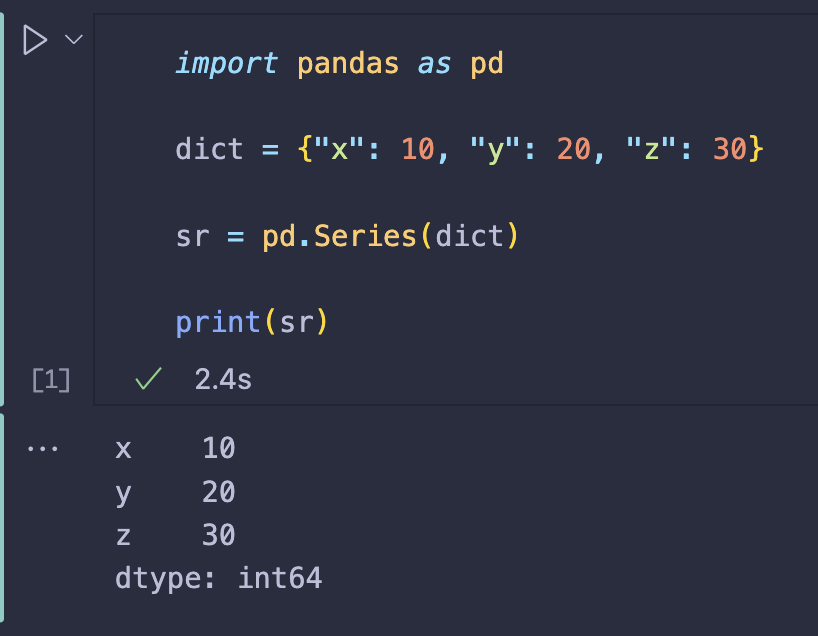
| import pandas as pd | |
| dict = {"x": 10, "y": 20, "z": 30} | |
| sr = pd.Series(dict) | |
| print(sr) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
예시2
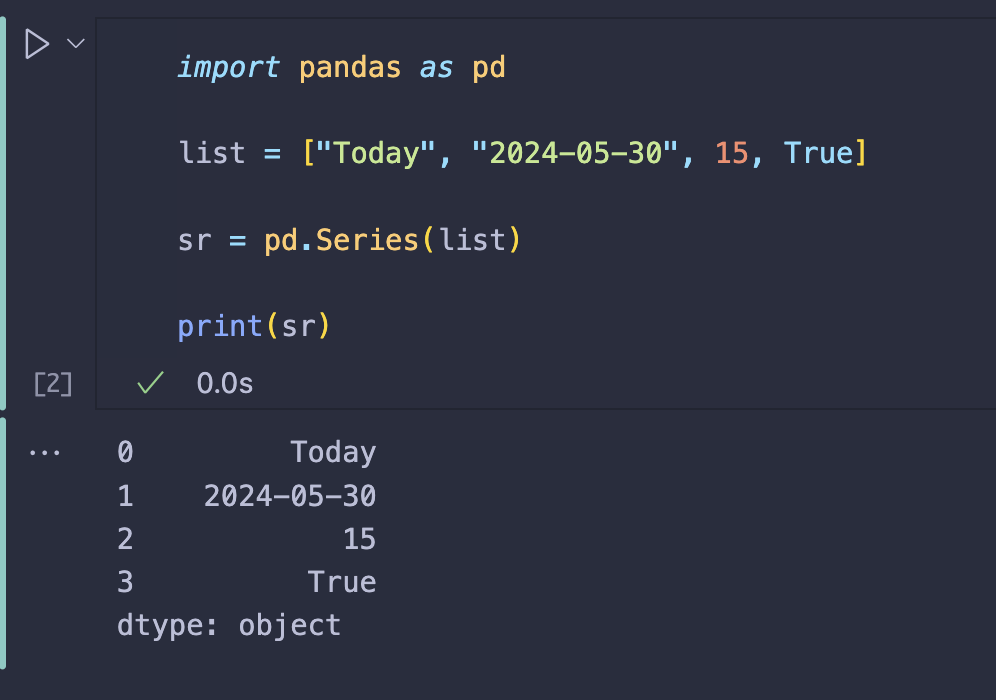
| import pandas as pd | |
| list = ["Today", "2024-05-30", 15, True] | |
| sr = pd.Series(list) | |
| print(sr) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
인덱스 구조
정수형 위치 인덱스와 인덱스 이름으로 두 가지가 있다.
위 두 가지를 이용하여 인덱스 배열 혹은 값(value)을 따로 선택할 수 있다.
| # 인덱스 배열 선택하기 | |
| Series객체.index | |
| # value 선택하기 | |
| Series객체.values |
예시
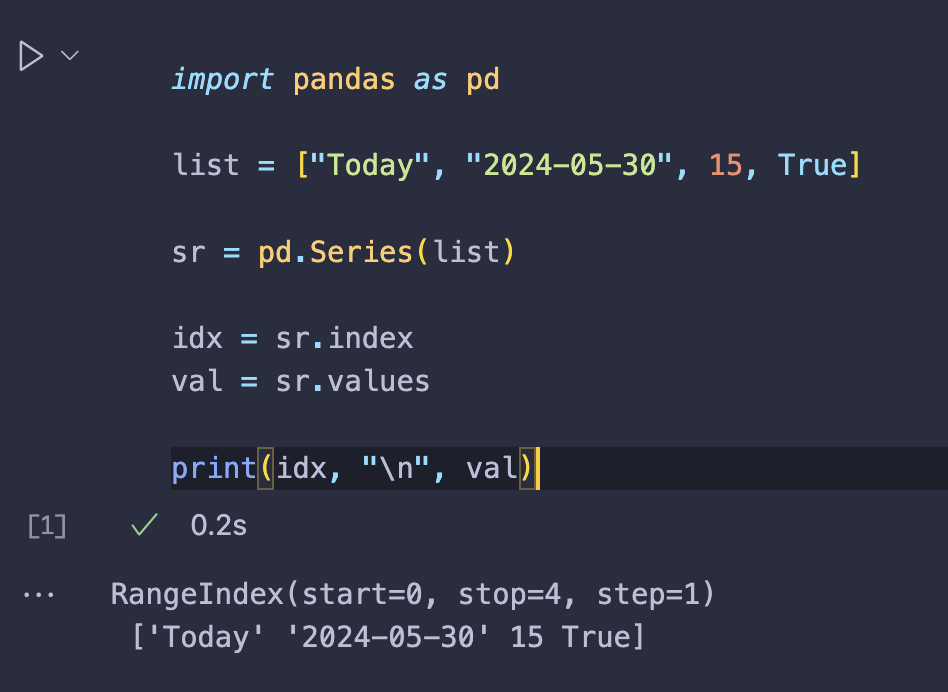
| import pandas as pd | |
| list = ["Today", "2024-05-30", 15, True] | |
| sr = pd.Series(list) | |
| idx = sr.index | |
| val = sr.values | |
| print(idx, "\n", val) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
인덱스 이름 정해주기
튜플(tuple)과 리스트(list)는 딕셔너리의 키에 해당하는 값이 없어서 시르즈로 변환할 때 정수형 위치 인덱스가 자동으로 지정된다.
이 때, 정수형 위치 인덱스 대신 인덱스 이름을 따로 지정할 수 있다.
Series() 함수의 index 옵션에 인덱스 이름을 직접 전달한다.
예시
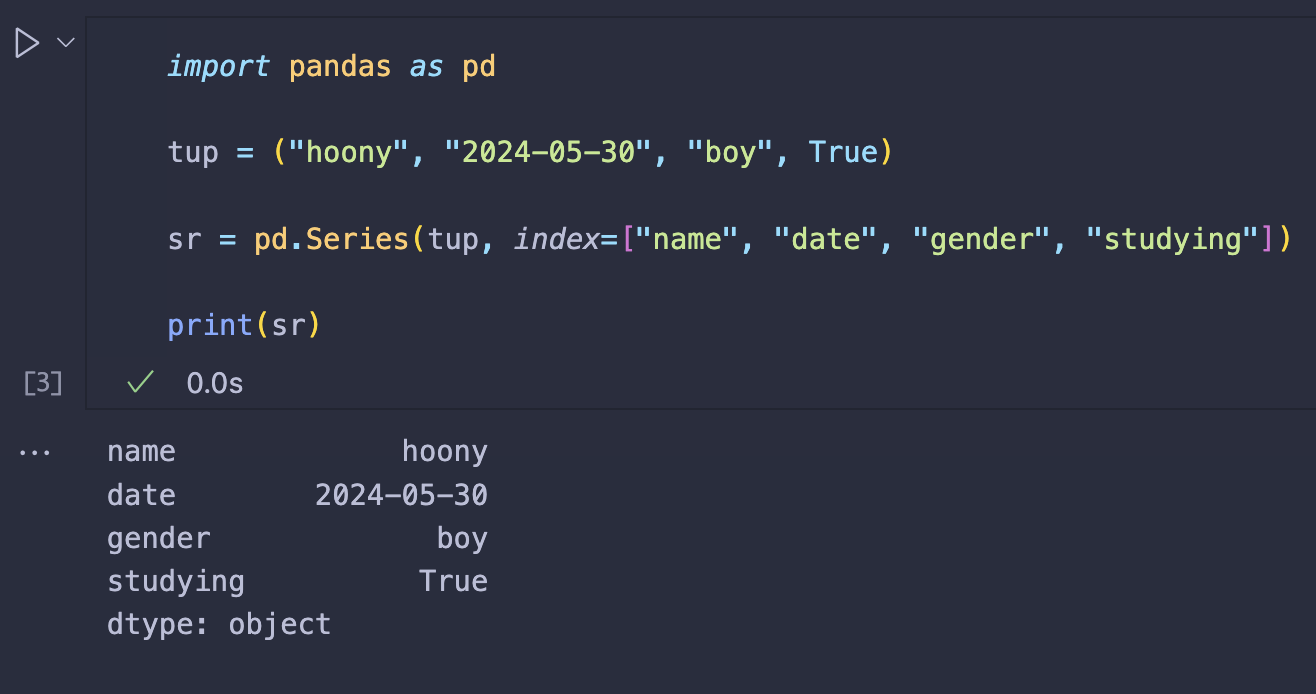
| import pandas as pd | |
| tup = ("hoony", "2024-05-30", "boy", True) | |
| sr = pd.Series(tup, index=["name", "date", "gender", "studying"]) | |
| print(sr) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
원소 선택
인덱스를 이용하여 원소를 선택할 수 있다.
정수형 위치 인덱스, 인덱스 이름을 사용하는 방법 두 가지가 있다.
정수형 위치 인덱스를 사용할 때는 대괄호([]) 안에 위치를 나타내는 숫자를 입력하고, 인덱스 이름을 사용할 때는 대괄호([]) 안에 "이름"과 같은 방식으로 사용한다.
예시1 - 한 개의 원소를 선택할 때
| import pandas as pd | |
| tup = ("hoony", "2024-05-30", "boy", True) | |
| sr = pd.Series(tup, index=["name", "date", "gender", "studying"]) | |
| print(sr[0]) # hoony | |
| print(sr["name"]) # hoony |
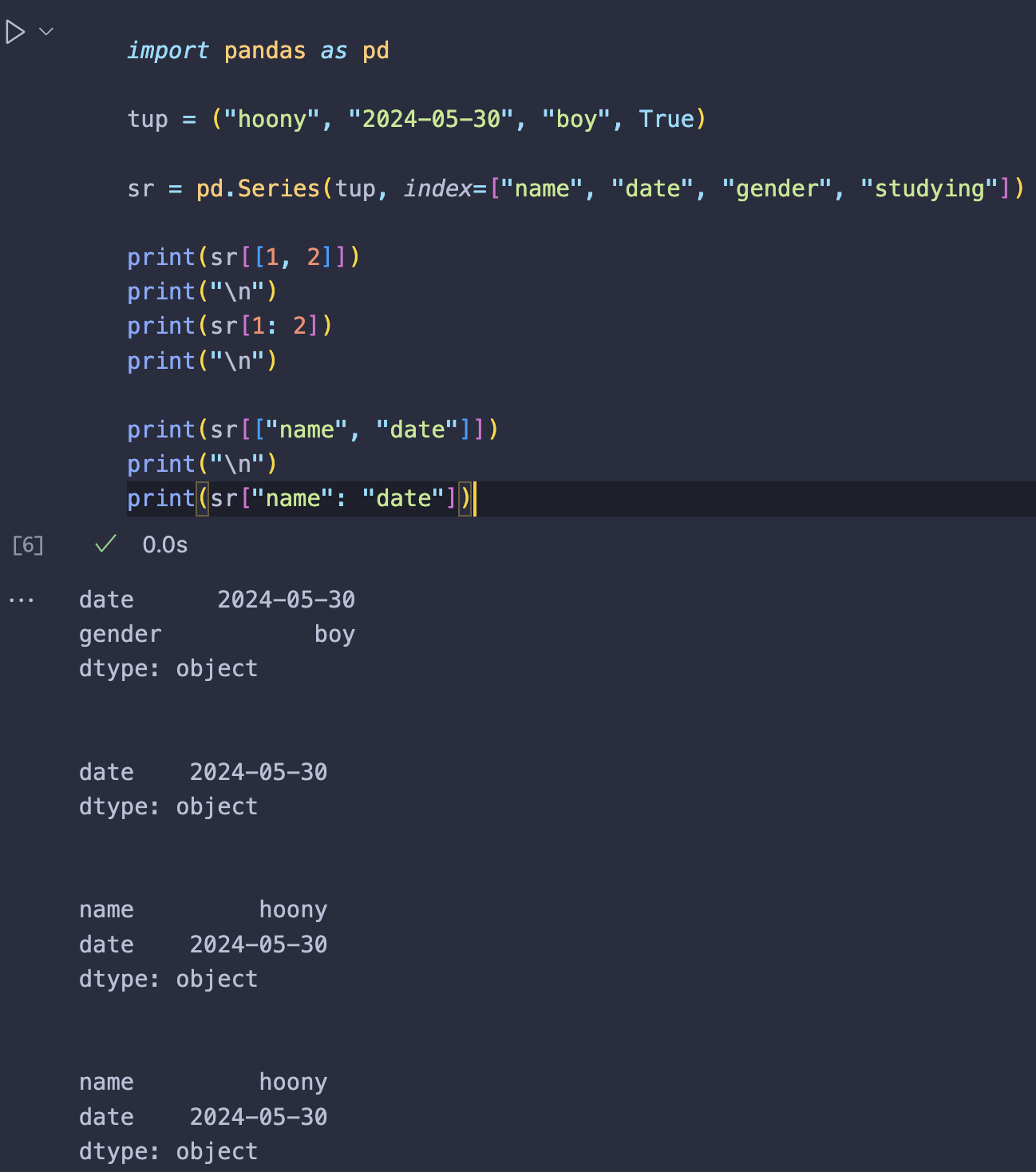
예시2 - 여러 개의 원소를 선택할 때
| import pandas as pd | |
| tup = ("hoony", "2024-05-30", "boy", True) | |
| sr = pd.Series(tup, index=["name", "date", "gender", "studying"]) | |
| print(sr[[1, 2]]) | |
| print("\n") | |
| print(sr[1: 2]) | |
| print("\n") | |
| print(sr[["name", "date"]]) | |
| print("\n") | |
| print(sr["name": "date"]) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
데이터프레임(DataFrame)
각각의 열은 시리즈 객체이다.
여러 개의 열벡터들이 같은 행 인덱스를 기준으로 줄지어 결합된 2차원 벡터 또는 행렬이다.
행과 열을 나타내기 위해, 행 인덱스(row index)와 열 이름(column name), 두 가지 종류의 주소를 사용한다.
열은 공통의 속성을 갖는 일련의 데이터(data)를 나타내고, 행은 개별 관측대상에 대한 다양한 속성 데이터들의 모음인 레코드(record)가 된다.
데이터프레임을 만들기 위해서는 같은 길이의 1차원 배열 여러 개가 필요하다.
사용 방법
| pandas.DataFrame(딕셔너리 객체) |
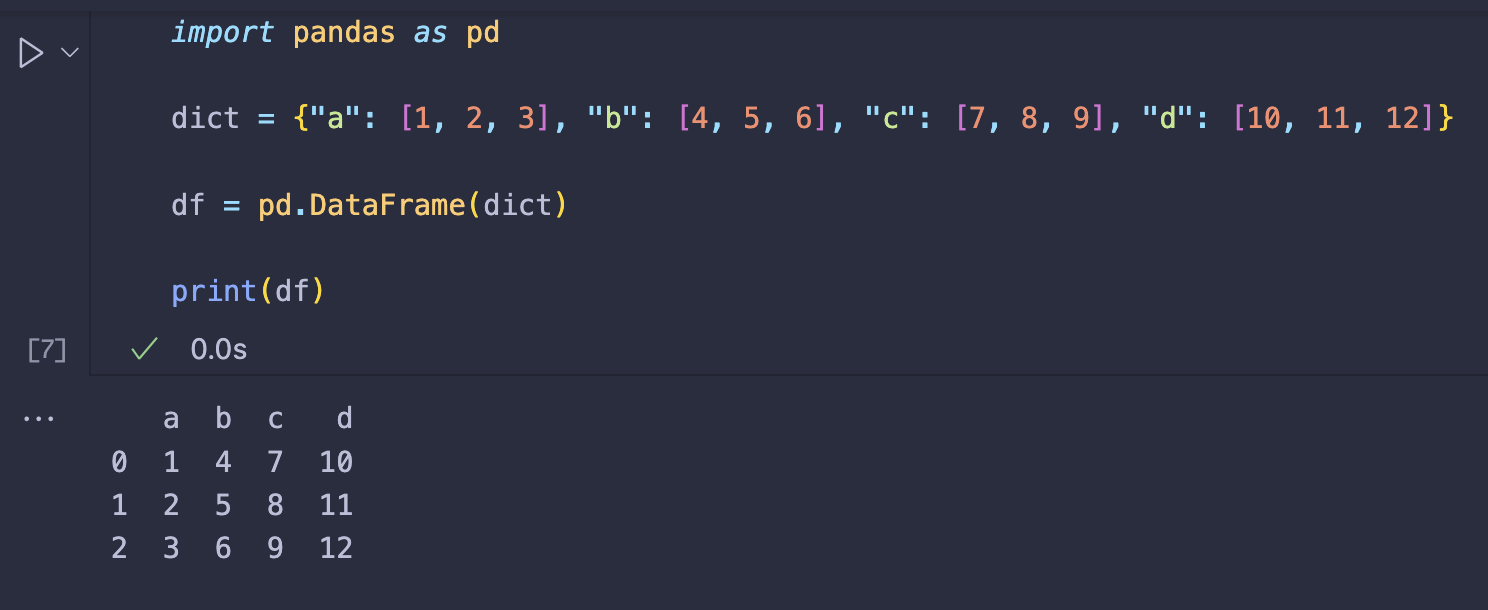
예시
| import pandas as pd | |
| dict = {"a": [1, 2, 3], "b": [4, 5, 6], "c": [7, 8, 9], "d": [10, 11, 12]} | |
| df = pd.DataFrame(dict) | |
| print(df) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
행 인덱스/ 열 이름 설정
DataFrame() 함수로 데이터프레임으로 변환할 때 행 인덱스와 열 이름 속성을 직접 지정할 수 있다.
index 옵션에 행 인덱스로 사용할 배열을 설정하고, columns 옵션에 열 이름으로 사용할 배열을 설정한다.
사용 방법
| pandas.DataFrame(2차원 배열, index = 행 인덱스 배열, columns = 열 이름 배열) |
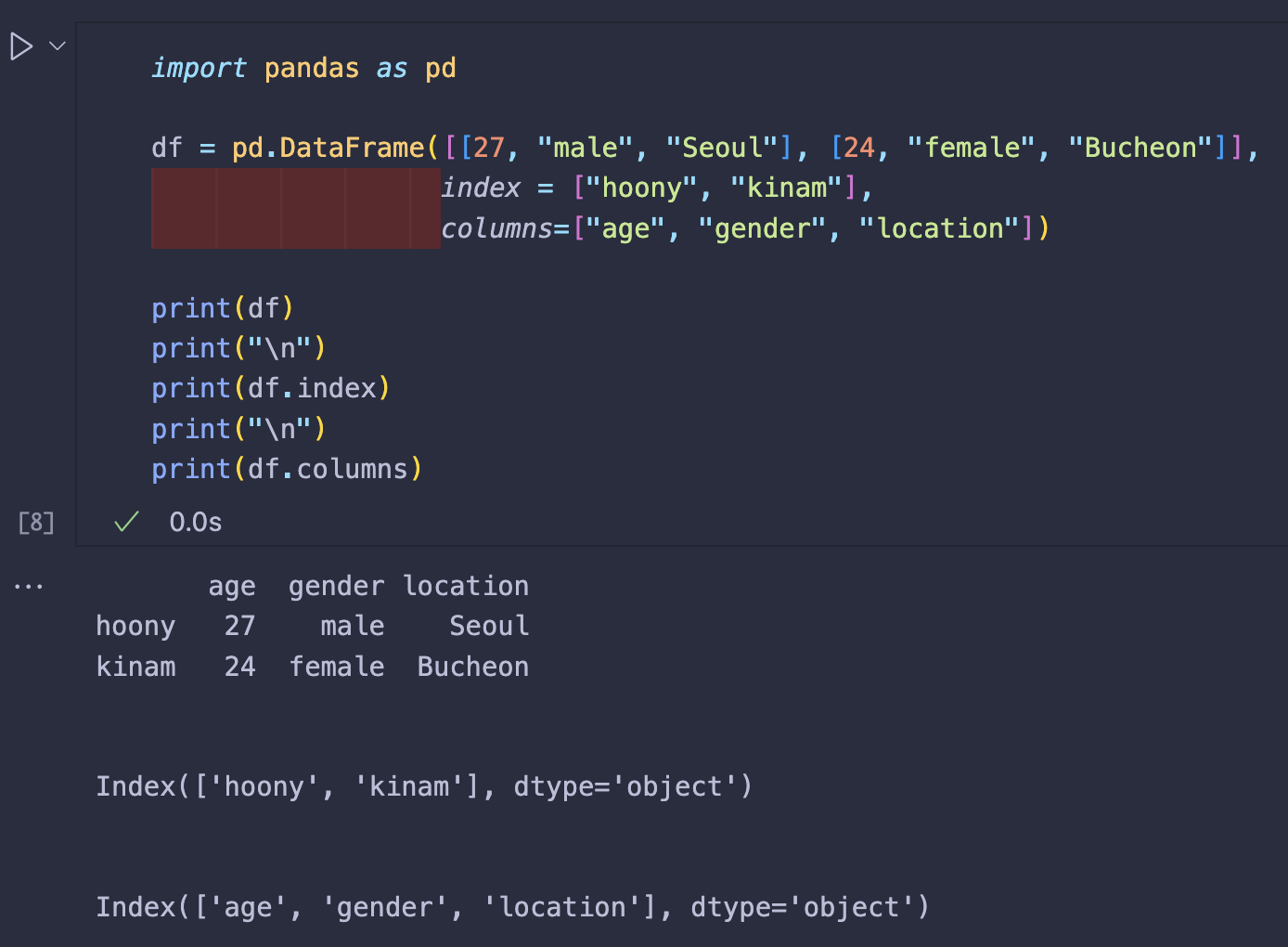
예시
| import pandas as pd | |
| df = pd.DataFrame([[27, "male", "Seoul"], [24, "female", "Bucheon"]], | |
| index = ["hoony", "kinam"], | |
| columns=["age", "gender", "location"]) | |
| print(df) | |
| print("\n") | |
| print(df.index) | |
| print("\n") | |
| print(df.columns) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
행 인덱스/열 이름 변경 1
.index와 .columns를 이용하여 행 인덱스와 열 이름을 변경할 수 있다.
사용 방법
| # 행 인덱스 변경 | |
| DataFrame 객체.index = 새로운 행 인덱스 배열 | |
| # 열 이름 변경 | |
| DataFrame 객체.columns = 새로운 열 이름 배열 |
예시
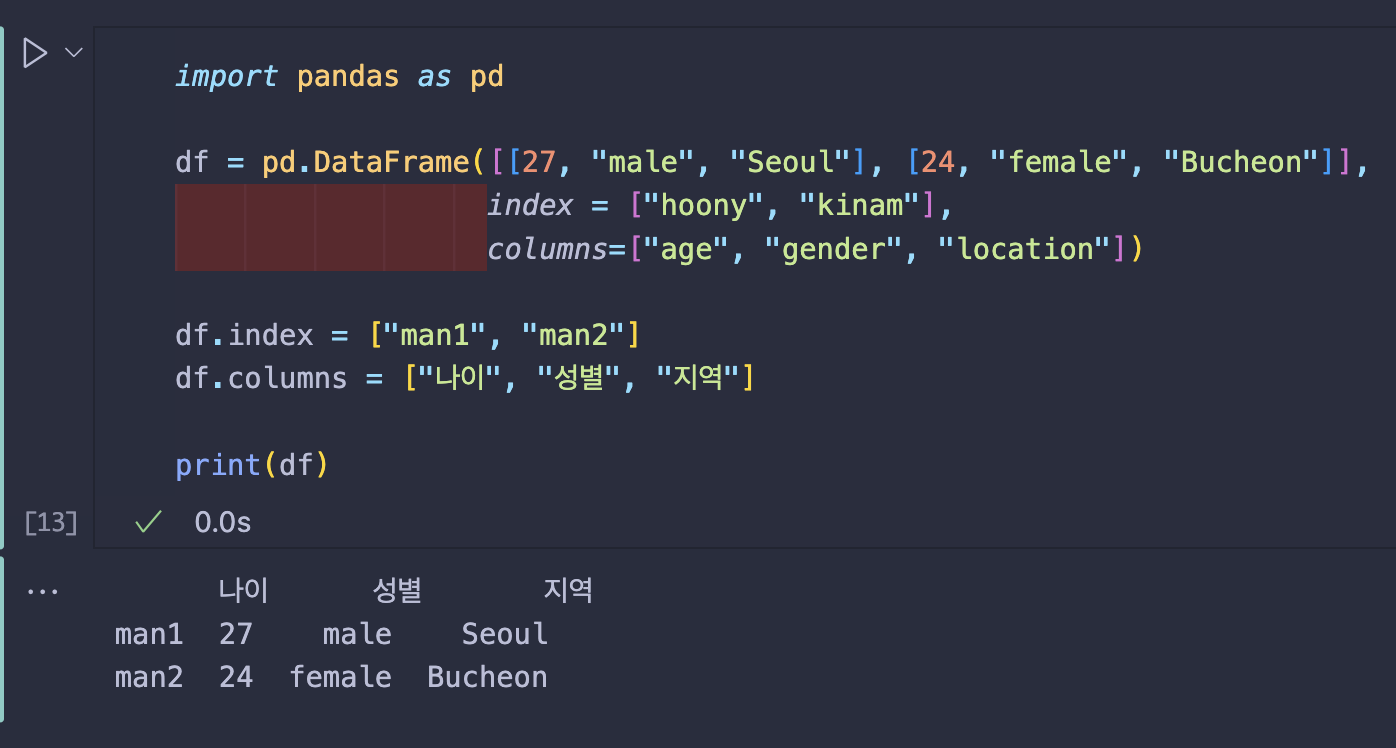
| import pandas as pd | |
| df = pd.DataFrame([[27, "male", "Seoul"], [24, "female", "Bucheon"]], | |
| index = ["hoony", "kinam"], | |
| columns=["age", "gender", "location"]) | |
| df.index = ["man1", "man2"] | |
| df.columns = ["나이", "성별", "지역"] | |
| print(df) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
행 인덱스/열 이름 변경 2
rename() 메서드를 적용하여 변경할 수 있다.
rename()을 사용하면 원본 객체를 직접 수정하는 것이 아니라 새로운 데이터프레임 객체를 반환한다.
원본 객체를 변경하려면 inplace=True 옵션을 사용한다.
사용 방법
| # 행 인덱스 변경 | |
| DataFrame 객체.rename(index={기존 인덱스 : 새로운 인덱스, ...}) | |
| # 열 이름 변경 | |
| DataFrame 객체.rename(columns={기존 이름 : 새로운 이름}, ...) |
예시
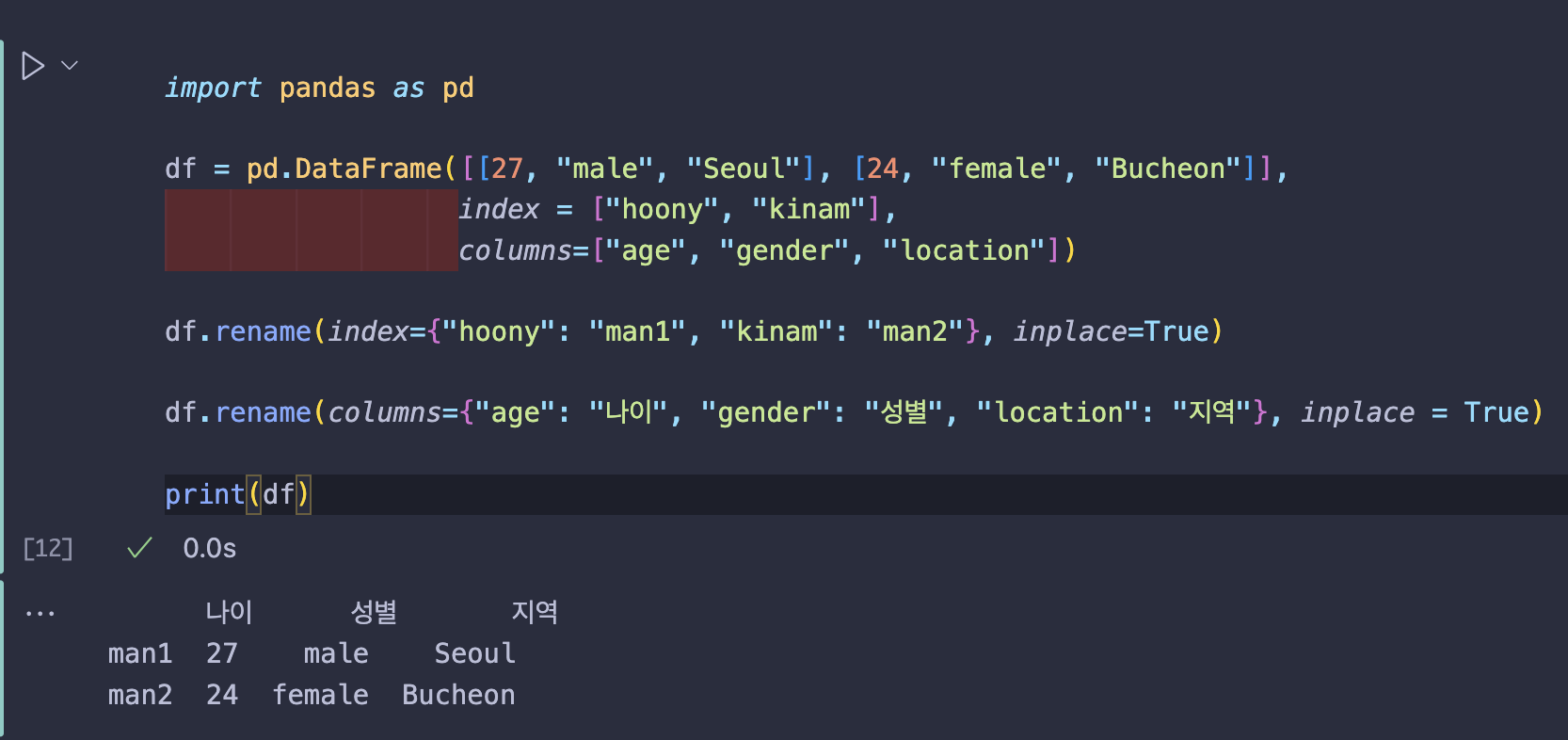
| import pandas as pd | |
| df = pd.DataFrame([[27, "male", "Seoul"], [24, "female", "Bucheon"]], | |
| index = ["hoony", "kinam"], | |
| columns=["age", "gender", "location"]) | |
| df.rename(index={"hoony": "man1", "kinam": "man2"}, inplace=True) | |
| df.rename(columns={"age": "나이", "gender": "성별", "location": "지역"}, inplace = True) | |
| print(df) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️
행/열 삭제
drop() 메서드를 사용하여 행 또는 열을 삭제한다.
행을 삭제할 때 axis=0 옵션을 입력하고, 열을 삭제할 때 axis=1 옵션을 입력한다. 이 때, axis=0이 default 값이다.
만약, 한번에 여러 개의 행 또는 열을 삭제하려면 리스트 형태로 입력한다.
drop() 메서드는 기존 객체를 변경하지 않고 새로운 객체를 반환한다. 그래서 원본 객체를 직접 변경하려면 inplace=True 옵션을 추가해주면된다.
사용 방법
| # 행 삭제 | |
| DataFrame 객체.drop(행 인덱스 또는 배열, axis=0) | |
| # 열 삭제 | |
| DataFrame 객체.drop(열 이름 또는 배열, axis=1) |
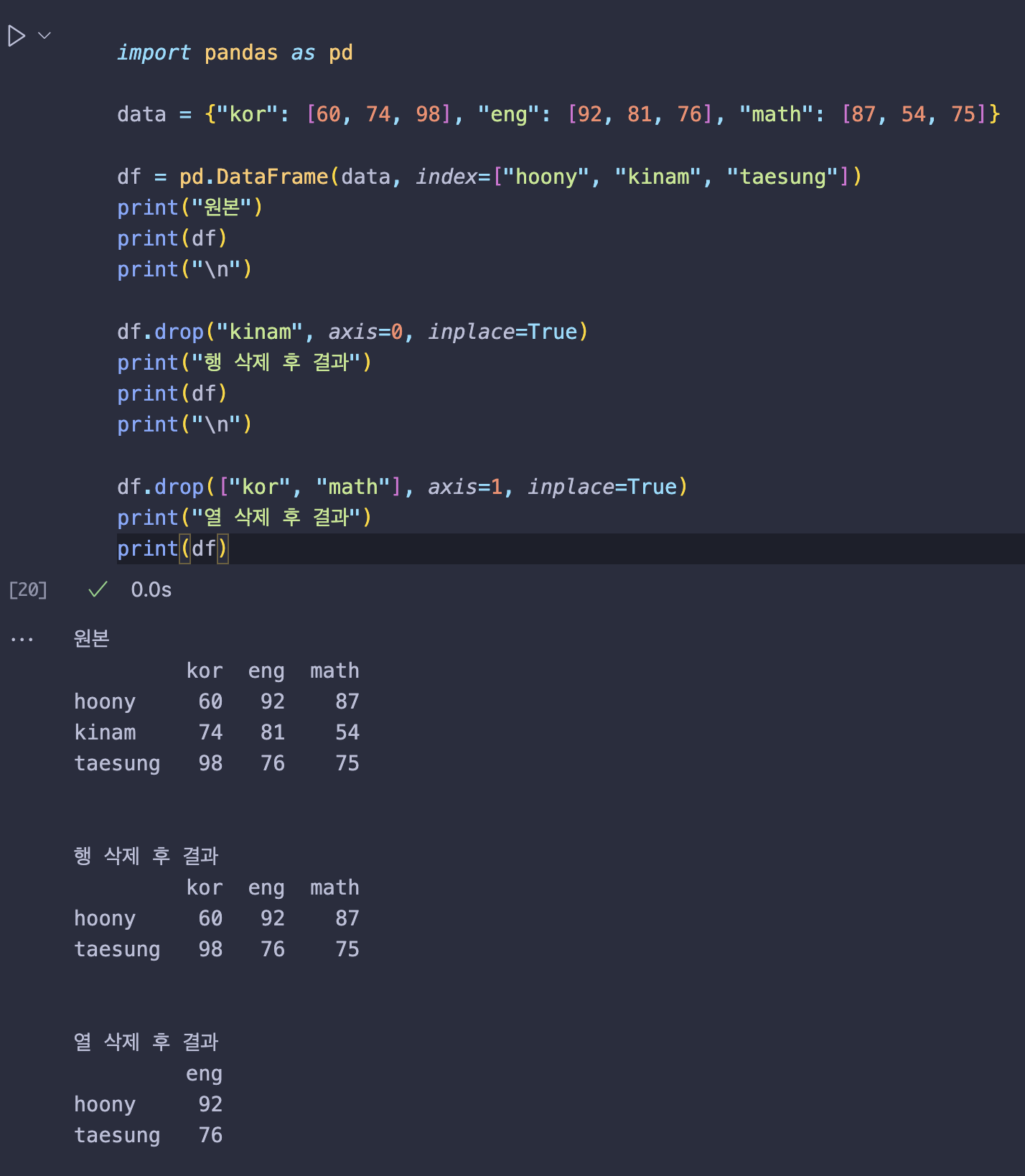
예시
| import pandas as pd | |
| data = {"kor": [60, 74, 98], "eng": [92, 81, 76], "math": [87, 54, 75]} | |
| df = pd.DataFrame(data, index=["hoony", "kinam", "taesung"]) | |
| print("원본") | |
| print(df) | |
| print("\n") | |
| df.drop("kinam", axis=0, inplace=True) | |
| print("행 삭제 후 결과") | |
| print(df) | |
| print("\n") | |
| df.drop(["kor", "math"], axis=1, inplace=True) | |
| print("열 삭제 후 결과") | |
| print(df) |
⬇️⬇️⬇️ 실행 결과 ⬇️⬇️⬇️